Geo-Replication/Multi-AR (Active)
The Active Geo-Replication (Multi-AZ/Multi-AR/Cross-Region) feature implements a mechanism to provide database redundancy within the same AWS region or in different regions (geo-redundancy). Active Geo-Replication asynchronously replicates committed transactions from a database to multiple copies of the database on different regions. The original database becomes the primary database of the continuous copy. Each continuous copy is referred to as an online secondary database. The primary database asynchronously replicates committed transactions to each of the online secondary databases. While at any given point, the online secondary data might be slightly behind the primary database (see Instance Type Comparison Table for more details), the online secondary data is guaranteed to always be transactionally consistent with changes committed to the primary database. Active Geo-Replication supports up to four* online secondaries.
One of the primary benefits of Active Geo-Replication is that it provides a database-level disaster recovery solution. Using Active Geo-Replication, you can configure a user database to replicate transactions to databases on different RDS or EC2 SQL Server within the same or different regions. Cross-region redundancy enables applications to recover from a permanent loss of a datacenter caused by natural disasters, catastrophic human errors, or malicious acts.
Another key benefit is that the online secondary databases are readable (standard RDS multi-zone replicas are not accessible, and multi-zone support is not available for all SQL Server types; CLOUDBASIC supports replication even for SQL Server Web Edition ). Therefore, an online secondary can act as a load balancer for read workloads such as reporting. While you can create an online secondary in a different region for disaster recovery, you could also have an online secondary in the same region on a different server. Both online secondary databases can be used to balance read only workloads serving clients distributed across several regions.
Other scenarios where Active Geo-Replication can be used include:
- Database migration: You can use Active Geo-Replication to migrate a database from one server to another online with zero downtime.
- Application upgrades: You can use the online secondary as a fail back option.
To achieve real business continuity, adding redundancy between data centers to relational storage is only part of the solution. Recovering an application (service) end-to-end after a disastrous failure requires recovery of all components that constitute the service and any dependent services. Examples of these components include the client software (for example, a browser with a custom JavaScript), web front ends, storage, and DNS. It is critical that all components are resilient to the same failures and become available within the recovery time objective (RTO) of your application. Therefore, you need to identify all dependent services and understand the guarantees and capabilities they provide. Then, you must take adequate steps to ensure that your service functions during the failover of the services on which it depends. For more information about designing solutions for disaster recovery, see the Cloud DR section.
Terms and Definitions
Disruptive Event - An occurrence that caused the disruption of application availability. A given disruptive event could be an infrastructure failure, a server component failure, a natural disaster, or a human or application error.
Recover Point Objective (RPO) - The time interval that defines the maximum acceptable duration in which the application can lose updates (data) while fully recovering from a disruptive event.
Recovery Time Objective (RTO) - The time interval that defines the maximum acceptable duration of unavailability before the application fully recovers from a disruptive event.
Estimated Recovery Time (ERT) - The estimated duration for the database to be fully functional after a restore/failover request.
Continuous Copy Relationship - The link between a primary database and an online secondary database with automatic data synchronization between them.
Active Geo-Replication - The process of continuously copying changes from a primary database to one or more online secondary databases in the same or different geographic regions.
Primary Region - An AWS region where the Active Geo-Replication primary database resides in normal circumstances.
Secondary Region - The AWS region where an online secondary database resides.
Primary Database - A database that has an online secondary database and is open for full application access.
Online Secondary Database - A read-only continuously updated copy of the primary database created in the same region or in a different region for the purposes of data redundancy. The online secondary database can be accessed online by the client for read-only queries, but cannot be updated until the continuous copy relationship with its primary is terminated.
Offline Secondary Database - A continuously updated copy of the primary database created in the AWS defined DR paired region for the purposes of data redundancy. The offline secondary database cannot be accessed online by the client until the continuous copy relationship with its primary is terminated.
Source Server - In a continuous copy relationship, the SQL Database server that hosts the primary database.
Target Server - In a continuous copy relationship, the AWS SQL Database server that hosts the online secondary database.
Planned Termination - The coordinated process of terminating the continuous copy relationship with full replication of all the committed transactions on the primary database. The duration of termination depends on the number of committed transactions.
Unplanned (Forced) Termination - The process of immediately terminating the continuous copy relationship without attempting to replicate all of the committed transactions on the primary database. The duration of this process does not depend on the number of committed transactions to the primary database.
Planned Failover - The process of switching application access to an online secondary database as part of a planned operation such as a disaster recovery drill. Planned failover does not require forced termination and so does not result in data loss.
Unplanned Failover - The process of switching the application access to an online secondary database after an unplanned disruptive event. Unplanned failover requires forced termination and is likely to result in data loss.
Seeding - The process of creating the initial transactionally consistent copy (snapshot) of the primary database before it can become the online secondary and start replicating the incoming updates.
Capabilities
The Active Geo-Replication feature provides the following essential capabilities:
- Automatic Asynchronous Replication: After an online secondary database has been seeded, updates to the primary database are asynchronously copied to the online secondary database automatically. This means that transactions are committed on the primary database before they are copied to the online secondary database. However, after seeding, the online secondary database is transactionally consistent at any given point in time. (Note: Asynchronous replication accommodates the latency that typifies wide-area networks by which remote datacenters are connected.)
- Multiple online secondary databases: Two or more online secondary databases increase redundancy and protection for the primary database and application. If multiple online secondary databases exist, the application will remain protected even if one of the online secondary databases fails. If there is only one online secondary database, and it fails, the application is exposed to higher risk until a new online secondary database is created.
- Readable online secondary databases: An application can access an online secondary database for read-only operations using the same security principals used for accessing the primary database. Continuous copy operations on the online secondary database take precedence over application access. Also, if the queries on the online secondary database cause prolonged table locking, transactions could eventually fail on the primary database.
- User-controlled termination for failover: Before you can failover an application to an online secondary database, the continuous copy relationship with the primary database must be terminated. Termination of the continuous copy relationship requires an explicit action by the application or an administrative script or manually via the portal. After termination, the online secondary database becomes a stand-alone database. It becomes a read-write database unless the primary database was a read-only database. Two forms of Termination of a Continuous Copy Relationship are described later in this topic.
Important
The online secondary must be configured to have the same or larger performance level as the primary. Changes to performance levels to the primary database are not automatically replicated to the secondaries. Any upgrades should be done on the secondary databases first and finally on the primary. There are two main reasons the online secondary should be at least the same size as the primary. The secondary must have enough capacity to process the replicated transactions at the same speed as the primary. If the secondary does not have, at minimum, the same capacity to process the incoming transactions, it could lag behind and eventually impact the availability of the primary. If the secondary does not have the same capacity as the primary, the failover may degrade the application’s performance and availability.
Continuous Copy Relationship Concepts
The following figure illustrates how Active Geo-Replication extends database redundancy across three AWS regions. The region that hosts the primary database is known as the primary or Master (M) region. The region that hosts the online secondary database is known as the secondary or Replica (R) region. In this figure, AWS North California is the primary region. AWS Singapore, Virginia and Australia are the secondary regions.
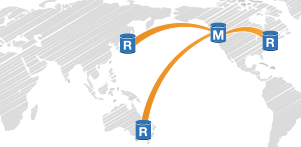
If the primary database becomes unavailable, terminating the continuous copy relationship for a given online secondary database makes the online secondary database a stand-alone database. At this point, the application can fail over and continue using the online secondary database. To provide resiliency in the event of a catastrophic failure of the datacenter or a prolonged outage in the primary region, at least one online secondary database needs to reside in a different region.
- Creating a Continuous Copy
You can only create a continuous copy of an existing database. Creating a continuous copy of an existing database is useful for adding geo-redundancy. A continuous copy can also be created to copy an existing database to a different RDS or EC2 SQL Server. Once created the secondary database is populated with the data copied from the primary database. This process is known as seeding. After seeding is complete each new transaction is replicated after it commits on the primary.
For information about how to create a continuous copy of an existing database, see Get Started - Configure Multi-AZ or Multi-AR with Readable Replicas.
- Preventing the Loss of Critical Data
Due to the high latency of wide area networks, continuous copy uses an asynchronous replication mechanism. This makes some data loss unavoidable if a failure occurs. However, some applications may not tolerate data loss. To protect these critical updates, an application developer can call the wait_for_database_copy_sync API method (available only for XtraLarge instances and coming in next version) of the CLOUDBASIC server immediately after committing the transaction. Calling wait_for_database_copy_sync blocks the calling thread until the last committed transaction has been replicated to the online secondary database. The procedure will wait until all queued transactions have been acknowledged by the online secondary database. wait_for_database_copy_sync is scoped to a specific continuous copy link. Any user with the connection rights to the primary database can call this procedure.
Caution
The delay caused by a wait_for_database_copy_sync procedure call might be significant. The delay depends on the length of the queue and on the available bandwidth. Avoid calling this procedure unless absolutely necessary.
- Termination of a Continuous Copy Relationship
The continuous copy relationship can be terminated at any time. Terminating a continuous copy relationship does not remove the secondary database. There are two methods of terminating a continuous copy relationship:
1. Planned Termination is useful for planned operations where data loss is unacceptable. A planned termination can only be performed on the primary database, after the online secondary database has been seeded. In a planned termination, all transactions committed on the primary database are replicated to the online secondary database first, and then the continuous copy relationship is terminated. This prevents loss of data on the secondary database.
2. Unplanned (Forced) Termination is intended for responding to the loss of either the primary database or one of its online secondary databases. A forced termination can be performed on either the primary database or the secondary database. Every forced termination results in the irreversible loss of the replication relationship between the primary database and the associated online secondary database. Additionally, forced termination causes the loss of any transactions that have not been replicated from the primary database. A forced termination terminates the continuous copy relationship immediately. In-flight transactions are not replicated to the online secondary database. Therefore, a forced termination can result in an irreversible loss of any transactions that have not been replicated from the primary database.
Warning
If the primary database has only one continuous copy relationship, after termination, updates to the primary database will no longer be protected.
For more information about how to terminate a continuous copy relationship, see Terminate a Continuous Copy Relationship.
Frequently Asked Questions
Q: Can I create the secondary database using a different AWS account ?
A: Yes. As long as SQL Server connectivity is allowed in both the Primary and Secondary firewalls, the replication can span multiple AWS accounts.
Q: Is the metadata in master replicated from the primary to the secondary databases?
A: No. Only the data in the primary database is replicated. The DMVs and all other metadata are specific to the database, and primary and secondary databases are considered different databases.
Q: Can I restore the database from a secondary?
A: Yes. You can access the backups and submit a restore request from either the primary database or the secondary database.