
TOP FAQs
Yes, cross-Region and in-Region read replicas for both RDS SQL Server and EC2 SQL Server read replicas are supported for all SQL Server editions, including SQL Server Standard and Web. In addition, RDS SQL Server Enterprise cross-Region read replicas are now supported by CLOUDBASIC for Amazon RDS SQL Server Read Replicas and Disaster Recovery (DR) on the AWS Marketplace.
Note: Cross-Region read replicas are not supported by the native RDS SQL Server Enterprise read replicas solution.
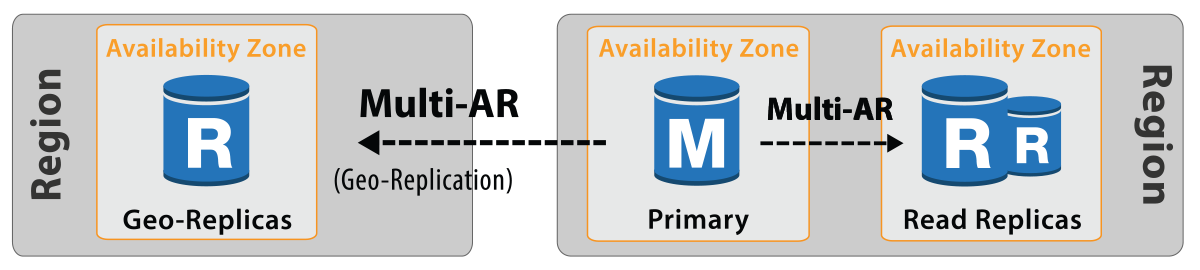
Unlike Amazon RDS Multi-AZ for SQL Server which creates non-readable replicas, CLOUDBASIC for Amazon RDS SQL Server Read Replicas and Disaster Recovery (DR) creates read replicas which can be used for reporting. Also CLOUDBASIC unlocks cross-Region read replicas for RDS SQL Server Standard, Enterprise and Web editions (for comparison of RDS SQL Server Enterprise read replicas and CLOUDBASIC RDS SQL Server read replicas go to next question).
Get started with a free trial of CLOUDBASIC for Amazon RDS SQL Server Read Replicas and Disaster Recovery (DR) on the AWS Marketplace
The native Amazon RDS SQL Server read replicas are in-Region only and are supported for the Enterprise edition only with RDS Multi-AZ enabled.
CLOUDBASIC for Amazon RDS SQL Server Read Replicas and Disaster Recovery (DR) supports both cross-Region and in-Region read replicas for SQL Server Enterprise, Standard and Web. RDS Multi-AZ is not required, but CLOUDBASIC RDS is compatible with RDS Multi-AZ for SQL Server. For more information see detailed comparison table In addition, CLOUDBASIC allows creation of substantially lower cost EC2/RDS SQL Server Standard read replicas from RDS SQL Server Enterprise primary source, and EC2/RDS SQL Server Web read replicas from RDS SQL Server Standard.
To learn about Cost Optimization Scenarios, go to https://cloudbasic.net/#costoptimization
Get started with a free trial of CLOUDBASIC for Amazon RDS SQL Server Read Replicas and Disaster Recovery (DR) on the AWS Marketplace
Yes, multiple read replicas (cross-Region and in-Region) for RDS SQL Server Standard, Enterprise and Web and EC2 SQL Server all editions are supported.
Get started with a free trial of CLOUDBASIC for Amazon RDS SQL Server Read Replicas and Disaster Recovery (DR) on the AWS Marketplace
CLOUDBASIC for Amazon RDS SQL Server Read Replicas and Disaster Recovery (DR) allows creation of substantially lower cost EC2/RDS SQL Server Standard read replicas from RDS SQL Server Enterprise primary source, and EC2/RDS SQL Server Web read replicas from RDS SQL Server Standard.
To learn about Cost Optimization Scenarios, go to https://cloudbasic.net/#costoptimization
Get started with a free trial of CLOUDBASIC for Amazon RDS SQL Server Read Replicas and Disaster Recovery (DR) on the AWS Marketplace
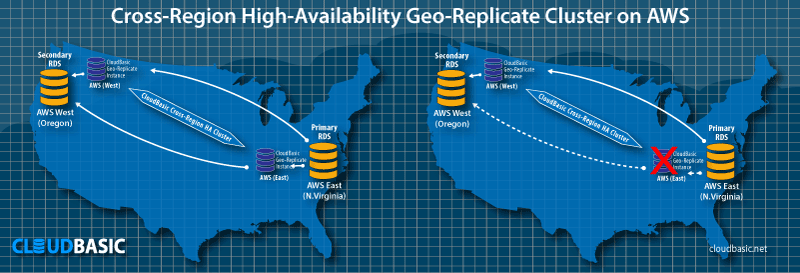
Yes, CLOUDBASIC for Amazon RDS SQL Server Read Replicas and Disaster Recovery (DR) allows 2 x CLOUDBASIC instances deployed in different availability zones (Multi-AZ) or multi-availability-regions (Multi-AR) to be clustered to achieve high availability replication processing. The replication workload is load balanced by default. If one server goes down the other one picks up the replication workload. Lower latency can be achieved by assigning affinity to the server replicating with lower lag, in which case the HA cluster configuration becomes master-slave (configurable per database).
Get started with a free trial of CLOUDBASIC for Amazon RDS SQL Server Read Replicas and Disaster Recovery (DR) on the AWS Marketplace
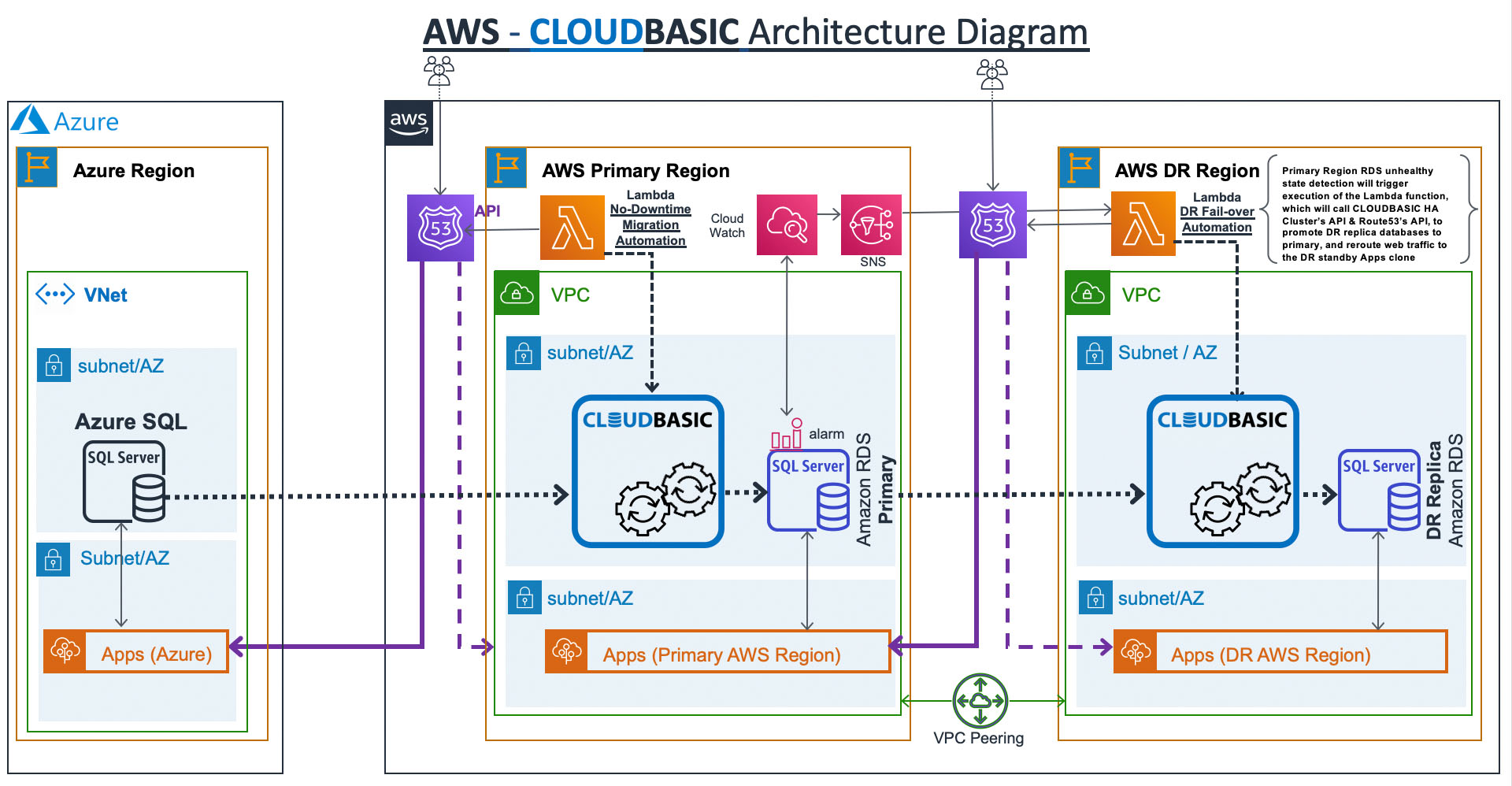
Yes, all SQL Server versions, including Managed Azure SQL Server Instances and Azure SQL Databases are supported.
In addition to the migration use case, CLOUDBASIC can also be used for deploying and testing cross-region RDS SQL Server disaster recovery in AWS environment (prior to migration cutover).
For more details, go to below AWS blog: https://aws.amazon.com/blogs/database/migrating-sql-server-databases-from-azure-to-aws-in-near-real-time-with-CLOUDBASIC/
CLOUDBASIC is available on the AWS Marketplace.
Deploy
