
Documentation

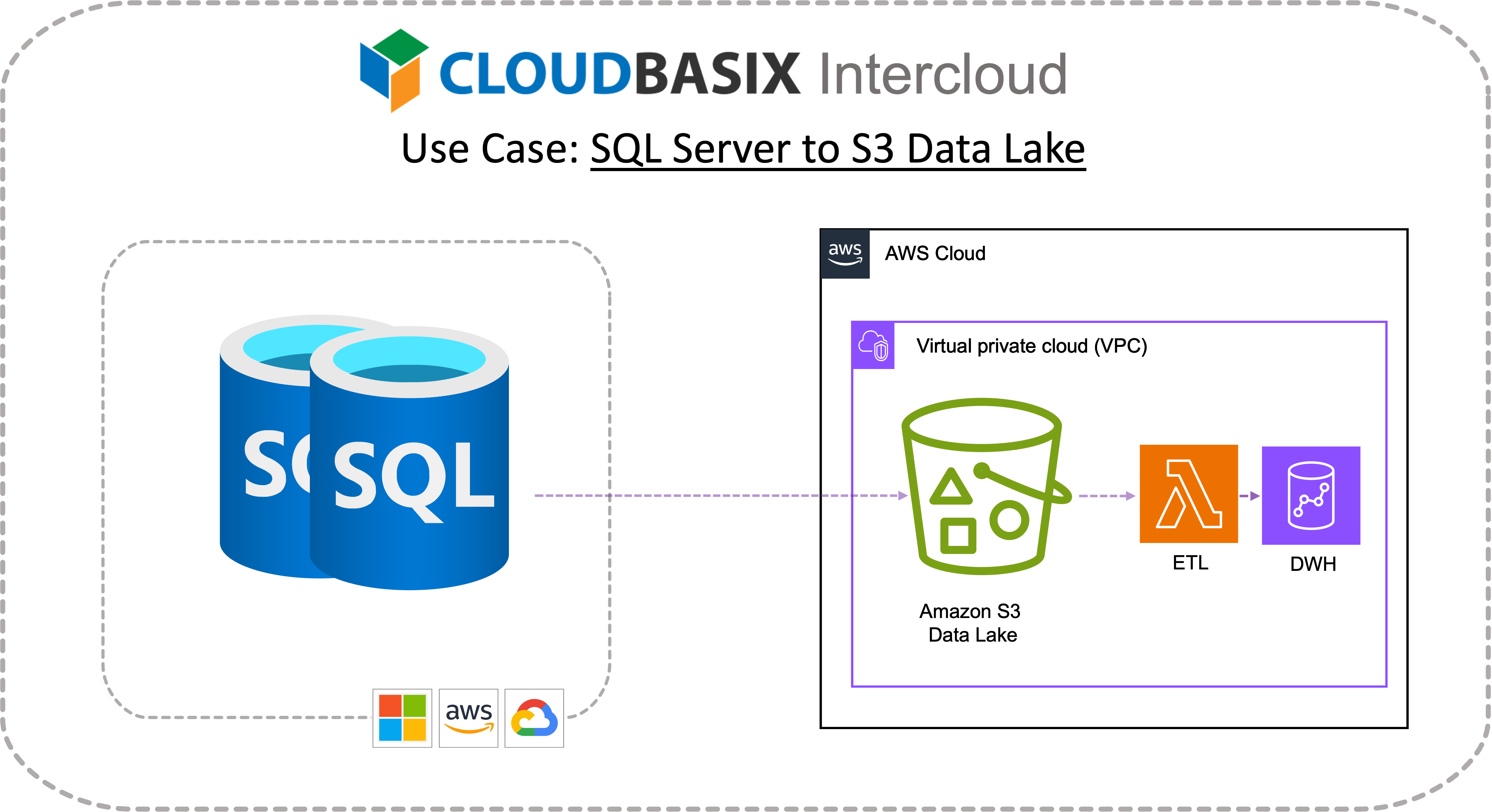
SQL Server to S3 Data Lake SCD Types 1-2 data feed
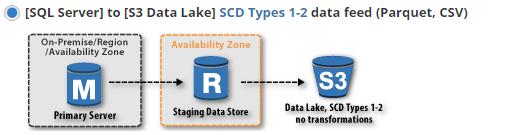
If you choose the third option [SQL Server] to [S3 Data Lake] SCD Types 1-2 data feed, you will arrive at the following screen:

Populate the required fields for the Master / Source Database and the Staging Data Source, and proceed to the next screen:
Supported flat file formats are Parquet (allowing faster querying of S3 Data Lakes from products such as Amazon Athena) and CSV. Data lakes can be partitioned in different structures depending on what format is suitable for your reporting/querying product (i.e. Amazon Glue, SAS etc)
